You have an Azure subscription that contains an Azure Synapse Analytics dedicated SQL pool named Pool1. Pool1 receives new data once every 24 hours.
You have the following function.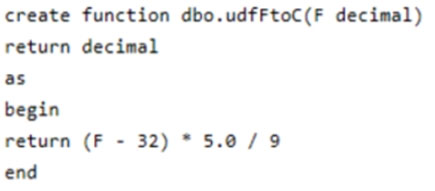
You have the following query.
The query is executed once every 15 minutes and the @parameter value is set to the current date.
You need to minimize the time it takes for the query to return results.
Which two actions should you perform? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.

esaade
Highly Voted 2 years, 4 months agof2a9aa5
Most Recent 11 months, 3 weeks agoiceberge
11 months, 4 weeks agoAccountHatz
1 year, 4 months agoSajadAhm
11 months, 1 week agodakku987
1 year, 6 months agoOldSchool
1 year, 9 months agokkk5566
1 year, 10 months agokkk5566
1 year, 10 months agokkk5566
1 year, 10 months agoMatt2000
1 year, 11 months agodumbled
2 years, 2 months agoLestrang
2 years, 6 months agoLestrang
2 years, 6 months agoLestrang
2 years, 5 months agoAccountHatz
1 year, 4 months agoKarforcerts
2 years, 7 months agoerhard
2 years, 8 months agokl8585
2 years, 8 months agorzeng
2 years, 8 months agoXinyuehong
2 years, 9 months agoanks84
2 years, 10 months ago