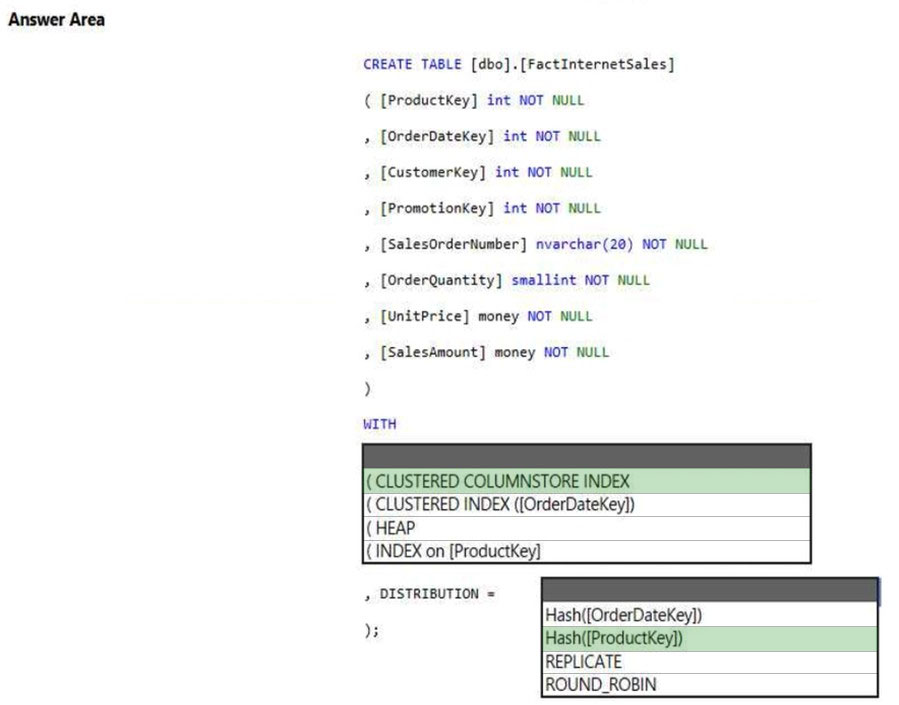
HOTSPOT -
You have an Azure Synapse Analytics dedicated SQL pool.
You need to create a table named FactInternetSales that will be a large fact table in a dimensional model. FactInternetSales will contain 100 million rows and two columns named SalesAmount and OrderQuantity. Queries executed on FactInternetSales will aggregate the values in SalesAmount and OrderQuantity from the last year for a specific product. The solution must minimize the data size and query execution time.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: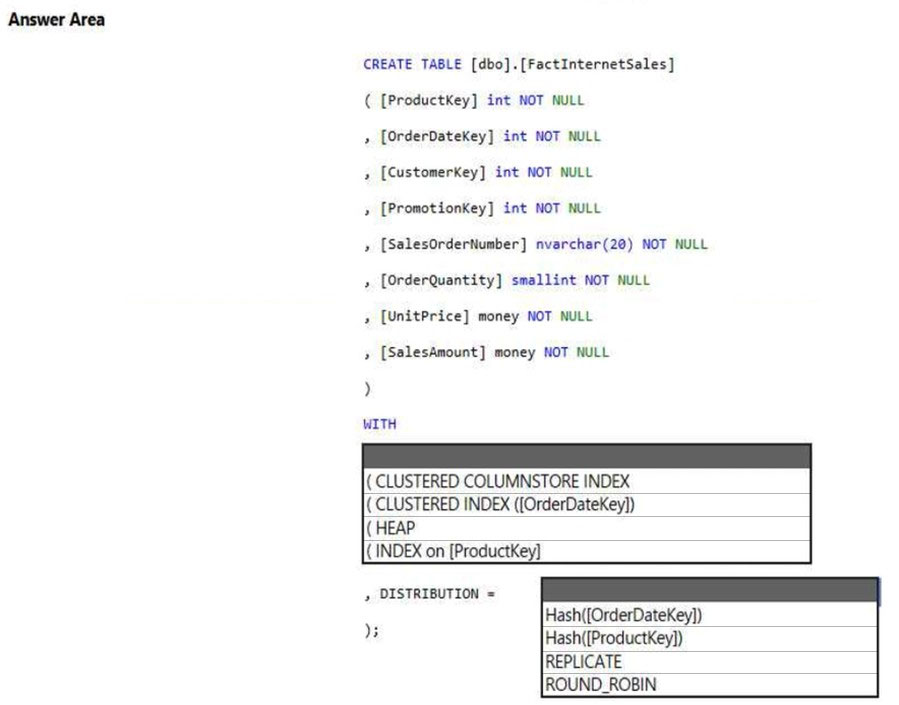


ted0809
Highly Voted 2 years, 6 months agotlb_20
1 year agohypersam
3 months, 3 weeks agoDusica
12 months agoData_Analytics
1 year, 6 months agoEuanm28
1 year, 6 months agoGikan
1 year, 3 months agoLestrang
Highly Voted 2 years, 3 months agoPey1nkh
Most Recent 2 months, 1 week agoDusica
12 months ago17lan
5 months agodgerok
1 year agokkk5566
1 year, 7 months agosmsme323
2 years, 7 months agoPhund
2 years, 7 months agoLestrang
2 years, 7 months agoanks84
2 years, 7 months ago