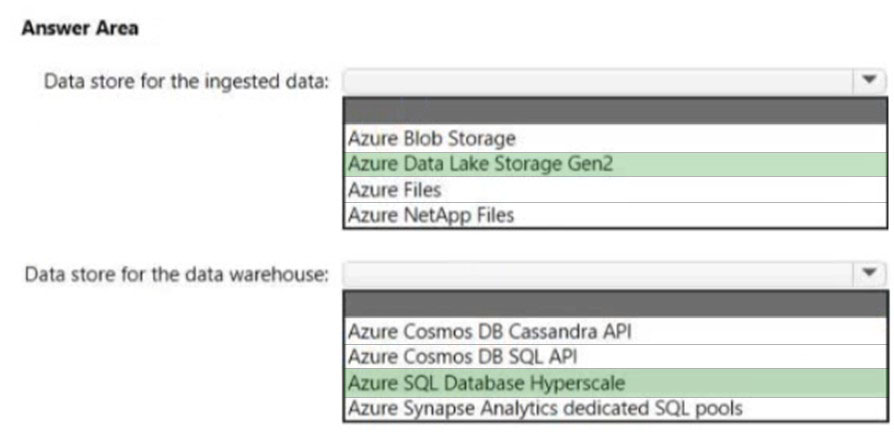
HOTSPOT -
You are designing a data storage solution to support reporting.
The solution will ingest high volumes of data in the JSON format by using Azure Event Hubs. As the data arrives, Event Hubs will write the data to storage. The solution must meet the following requirements:
✑ Organize data in directories by date and time.
✑ Allow stored data to be queried directly, transformed into summarized tables, and then stored in a data warehouse.
✑ Ensure that the data warehouse can store 50 TB of relational data and support between 200 and 300 concurrent read operations.
Which service should you recommend for each type of data store? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: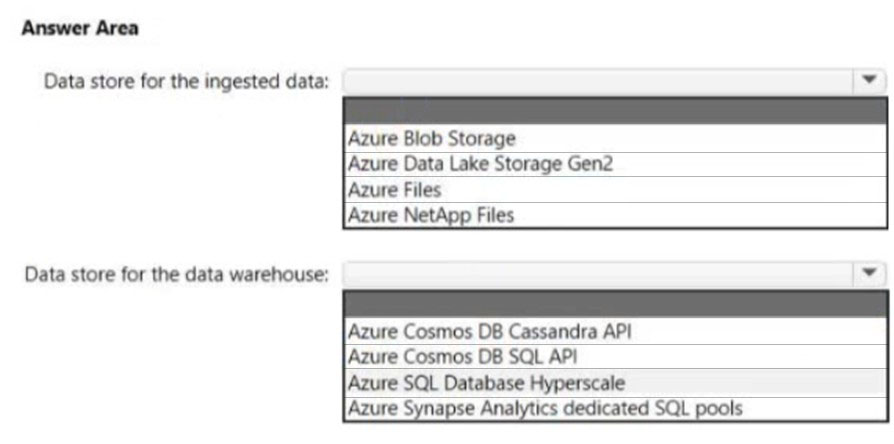
Snownoodles
Highly Voted 2 years, 6 months agoNotMeAnyWay
Highly Voted 1 year, 7 months ago[Removed]
Most Recent 3 months, 3 weeks agoTeerawee
5 months, 3 weeks ago23169fd
8 months, 2 weeks agojosola
6 months ago23169fd
8 months, 2 weeks agoChenn
10 months agojosola
6 months agovarinder82
11 months, 2 weeks agopeterp007
1 year, 2 months agoPaul_white
1 year, 3 months agomehak2020
1 year, 6 months agoBigbluee
1 year, 11 months agoNotMeAnyWay
1 year, 11 months agoHelice
1 year, 11 months agoHelice
1 year, 11 months agozellck
2 years agoabxc
2 years agoPutra19
2 years ago