Suggested Answer:
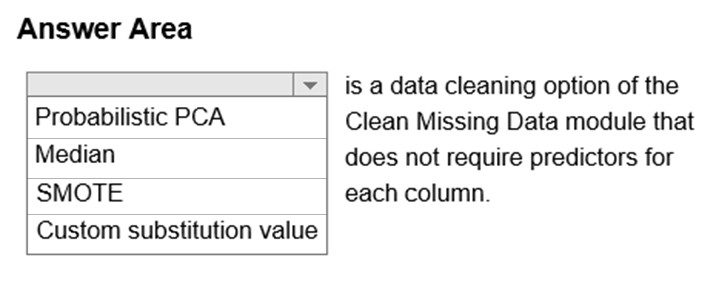
Replace using Probabilistic PCA: Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column. Instead, it approximates the covariance for the full dataset. Therefore, it might offer better performance for datasets that have missing values in many columns. Reference: https://docs.microsoft.com/en-us/azure/machine-learning/studio-module-reference/clean-missing-data
Replace using Probabilistic PCA: Replaces the missing values by using a linear model that analyzes the correlations between the columns and estimates a low-dimensional approximation of the data, from which the full data is reconstructed. The underlying dimensionality reduction is a probabilistic form of Principal Component Analysis (PCA), and it implements a variant of the model proposed in the Journal of the Royal Statistical Society, Series B 21(3), 611–622 by Tipping and Bishop.
Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column. Instead, it approximates the covariance for the full dataset. Therefore, it might offer better performance for datasets that have missing values in many columns.
https://learn.microsoft.com/en-us/previous-versions/azure/machine-learning/studio-module-reference/clean-missing-data
correct.. Outdated but in previous versions it says
Replace using Probabilistic PCA: Replaces the missing values by using a linear model that analyzes the correlations between the columns and estimates a low-dimensional approximation of the data, from which the full data is reconstructed. The underlying dimensionality reduction is a probabilistic form of Principal Component Analysis (PCA), and it implements a variant of the model proposed in the Journal of the Royal Statistical Society, Series B 21(3), 611–622 by Tipping and Bishop.
Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column. Instead, it approximates the covariance for the full dataset. Therefore, it might offer better performance for datasets that have missing values in many columns.
I think this is an outdated question.
as of may 2024, PCA is no longer in the clean missing data module.
reference: https://learn.microsoft.com/en-us/azure/machine-learning/component-reference/clean-missing-data?view=azureml-api-2
however, in the past, PCA did in the clean missing data module.
reference:https://learn.microsoft.com/en-us/previous-versions/azure/machine-learning/studio-module-reference/clean-missing-data
at the time of the question was created, PCA may be correct.
but now, i thick is either median or custom substitution value.
answer is 100% correct ...
Replace using Probabilistic PCA: ...
Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column.
https://learn.microsoft.com/en-us/previous-versions/azure/machine-learning/studio-module-reference/clean-missing-data
It can't be "A. Probabilistic PCA" because it isn't an option for the Clean Missing Data module. Here is the reference: https://learn.microsoft.com/en-us/azure/machine-learning/component-reference/clean-missing-data?view=azureml-api-2
It could be "D. Custom Substitution Value". The option "B. Median" isn't the exact option for the module which it's "Replace with median".
Qutote "Replace using Probabilistic PCA: Replaces the missing values by using a linear model that analyzes the correlations between the columns and estimates a low-dimensional approximation of the data, from which the full data is reconstructed. The underlying dimensionality reduction is a probabilistic form of Principal Component Analysis (PCA), and it implements a variant of the model proposed in the Journal of the Royal Statistical Society, Series B 21(3), 611–622 by Tipping and Bishop.
Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column."
Reference https://learn.microsoft.com/en-us/previous-versions/azure/machine-learning/studio-module-reference/clean-missing-data#:~:text=this%20option%20has%20the%20advantage%20of%20not%20requiring%20the%20application%20of%20predictors%20for%20each%20column.
Correct answer is medain - it only calulates the medain from the given column, no other columns required
pca - needs predictors to calculate the probabilities
smote - needs predictors to generate synthetic samples for the minority class
csv - doesn't really need predictors per se, but still requires some knoweldge about the data to pick the right value
One data cleaning option that does not require predictors for each column in the Clean Missing Data module is the "Replace with mean" option. This option replaces missing values in a column with the mean of the available values in that column
All these options are false
A
https://learn.microsoft.com/en-us/previous-versions/azure/machine-learning/studio-module-reference/clean-missing-data
"Replace using Probabilistic PCA: Replaces the missing values by using a linear model that analyzes the correlations between the columns and estimates a low-dimensional approximation of the data, from which the full data is reconstructed. The underlying dimensionality reduction is a probabilistic form of Principal Component Analysis (PCA), and it implements a variant of the model proposed in the Journal of the Royal Statistical Society, Series B 21(3), 611–622 by Tipping and Bishop.
Compared to other options, such as Multiple Imputation using Chained Equations (MICE), this option has the advantage of not requiring the application of predictors for each column. Instead, it approximates the covariance for the full dataset. Therefore, it might offer better performance for datasets that have missing values in many columns."
A) Probabilistic PCA and C) SMOTE are not data cleaning options in the clean missing data module.
Probabilistic PCA is a technique used for dimensionality reduction and feature extraction in machine learning, and it is not specifically designed to handle missing data.
SMOTE (Synthetic Minority Over-sampling Technique) is a technique used for dealing with imbalanced datasets in machine learning, and it is not designed to handle missing data.
Therefore, the correct answer to the question "..... is a data cleaning option of the clean missing data module that does not require predictors for each column" is either B) Median or D) Custom substitution value.
This section is not available anymore. Please use the main Exam Page.DP-100 Exam Questions
Log in to ExamTopics
Sign in:
Community vote distribution
A (35%)
C (25%)
B (20%)
Other
Most Voted
A voting comment increases the vote count for the chosen answer by one.
Upvoting a comment with a selected answer will also increase the vote count towards that answer by one.
So if you see a comment that you already agree with, you can upvote it instead of posting a new comment.


pancman
Highly Voted 3 years agorishi_ram
Highly Voted 1 year, 11 months agogeethavkr
Most Recent 8 months, 2 weeks agokay1101
11 months agoInversaRadice
1 year, 4 months agoeternaleclipse
1 year, 6 months agoIvanTT
1 year, 6 months agojames2033
1 year, 6 months agorakeshmk
1 year, 7 months agoPradhanManva
1 year, 7 months agoMarinaMijailovic
2 years agoTruman
2 years agoVic9
2 years agophdykd
2 years, 2 months agoPeeking
2 years, 2 months agoranjsi01
3 years, 2 months ago