HOTSPOT -
You are building an Azure Data Factory solution to process data received from Azure Event Hubs, and then ingested into an Azure Data Lake Storage Gen2 container.
The data will be ingested every five minutes from devices into JSON files. The files have the following naming pattern.
/{deviceType}/in/{YYYY}/{MM}/{DD}/{HH}/{deviceID}_{YYYY}{MM}{DD}HH}{mm}.json
You need to prepare the data for batch data processing so that there is one dataset per hour per deviceType. The solution must minimize read times.
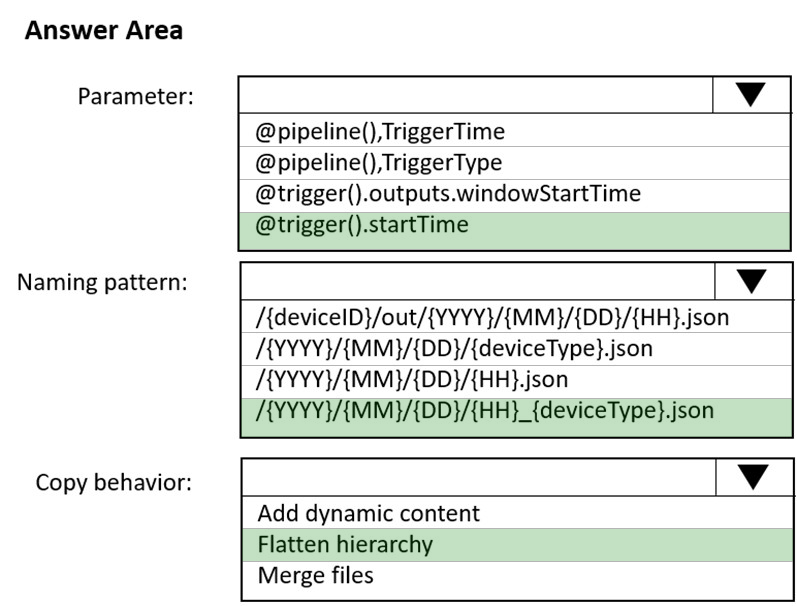
How should you configure the sink for the copy activity? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: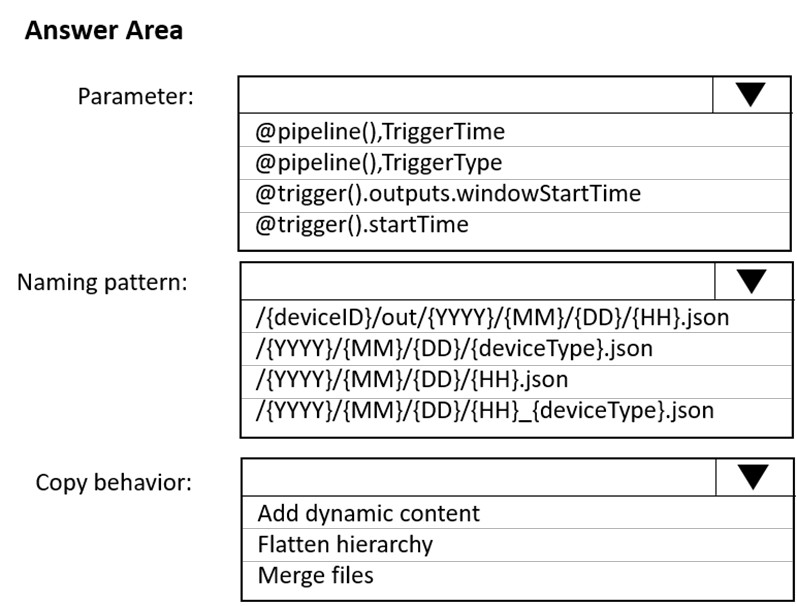
ItHYMeRIsh
Highly Voted 3 years, 1 month agoBro111
2 years, 1 month agosensaint
2 years, 1 month agoonyerleft
Highly Voted 3 years, 1 month agoDavico93
2 years, 7 months agorenan_ineu
Most Recent 4 months, 1 week agoELJORDAN23
1 year agoj888
12 months agoblazy002
1 year, 1 month agophydev
1 year, 3 months agoChemmangat
1 year, 4 months agokkk5566
1 year, 4 months agopavankr
1 year, 6 months agorocky48
1 year, 8 months agorzeng
2 years, 3 months agoDeeksha1234
2 years, 5 months agoRafafouille76
2 years, 11 months agokamil_k
2 years, 10 months agoJaws1990
3 years agoCanary_2021
3 years agojv2120
3 years, 1 month agotony4fit
3 years, 1 month agoAditya0891
2 years, 7 months ago