HOTSPOT -
Your Azure Machine Learning workspace has a dataset named real_estate_data. A sample of the data in the dataset follows.
You want to use automated machine learning to find the best regression model for predicting the price column.
You need to configure an automated machine learning experiment using the Azure Machine Learning SDK.
How should you complete the code? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: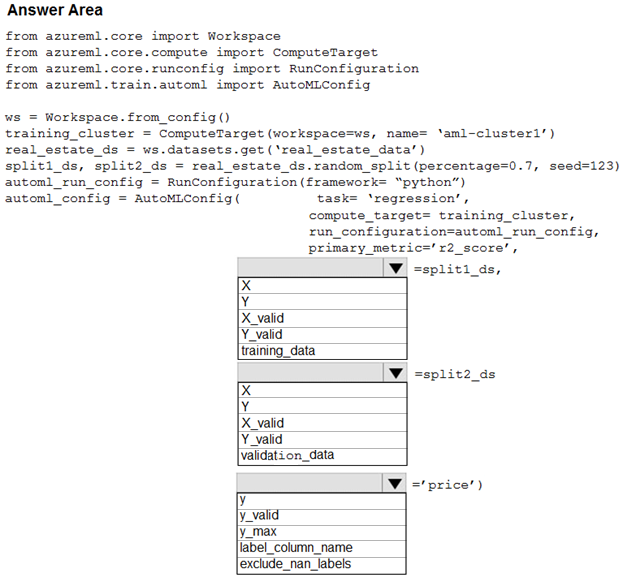


treadst0ne
Highly Voted 3 years, 7 months agoMatt2000
Most Recent 11 months, 1 week agoorionduo
1 year, 4 months agoRoohiSaanjh
2 years, 9 months agohargur
3 years, 2 months agoVJPrakash
3 years, 5 months agoljljljlj
3 years, 6 months ago