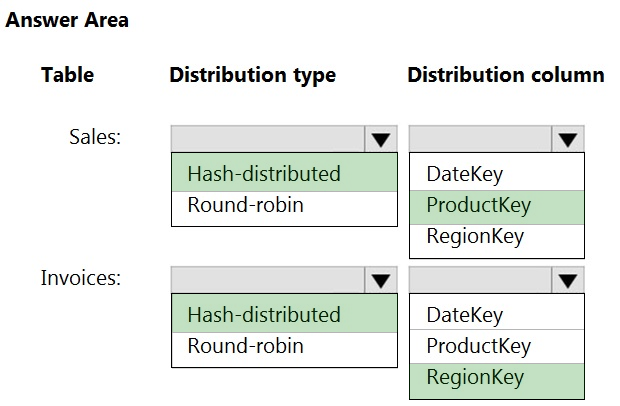
HOTSPOT -
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey.
There are 120 unique product keys and 65 unique region keys.
Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew.
What should you recommend? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area: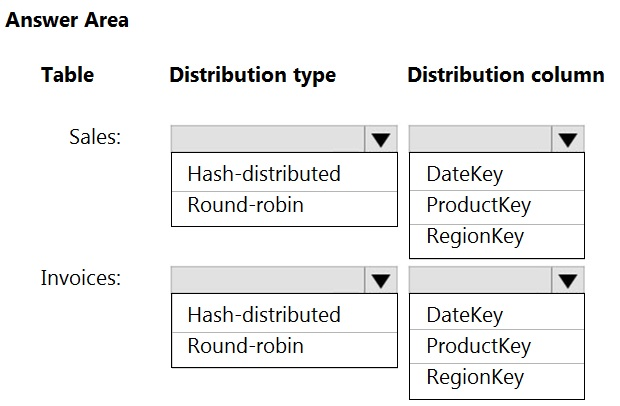

lara_mia1
Highly Voted 3 years, 10 months agoMarcello83
3 years, 9 months agoniceguy0371
3 years, 8 months agosdokmak
2 years, 10 months agovblessings
3 years, 8 months agoRob77
Highly Voted 3 years, 11 months agoploer
3 years, 2 months agoEvanG
Most Recent 6 months, 3 weeks agoevangelist
9 months agoDusica
11 months, 3 weeks agokkk5566
1 year, 7 months ago[Removed]
1 year, 8 months agoDusica
11 months, 3 weeks agodom271219
2 years, 7 months agoDeeksha1234
2 years, 8 months agoNishikag
2 years, 9 months agoRemedios79
2 years, 9 months agokiranSargar
3 years, 1 month agoDarioEtna
3 years, 8 months agoLucky_me
3 years, 3 months agoAditya0891
2 years, 10 months agoDarioEtna
3 years, 8 months agoAmalbenrebai
3 years, 8 months agozarga
3 years, 9 months agoBrennaFrenna
3 years, 10 months agotubis
3 years, 10 months agoPreben
3 years, 10 months agopatricka95
3 years, 9 months ago