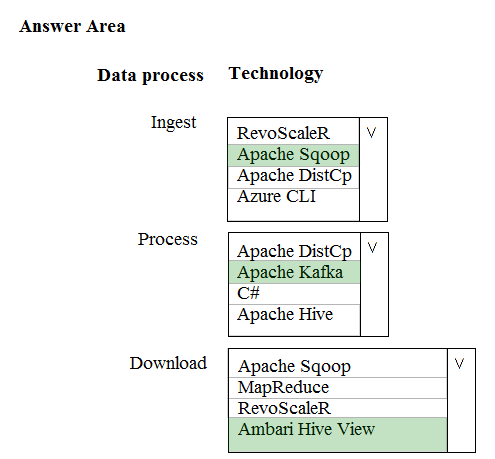
HOTSPOT -
A company is deploying a service-based data environment. You are developing a solution to process this data.
The solution must meet the following requirements:
✑ Use an Azure HDInsight cluster for data ingestion from a relational database in a different cloud service
✑ Use an Azure Data Lake Storage account to store processed data
✑ Allow users to download processed data
You need to recommend technologies for the solution.
Which technologies should you use? To answer, select the appropriate options in the answer area.
Hot Area: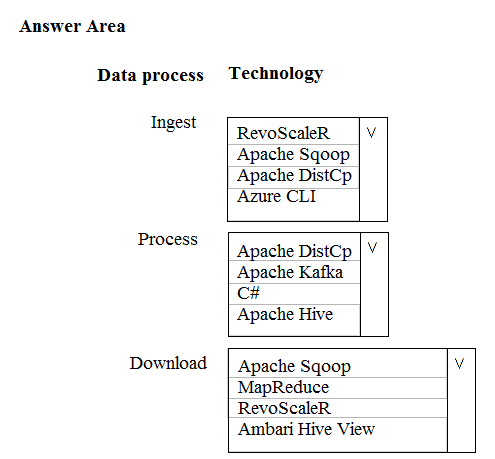

unidigm
3 years, 11 months agoKratik
3 years, 11 months agoHassan_Mazhar_Khan
4 years agotucho
4 years ago