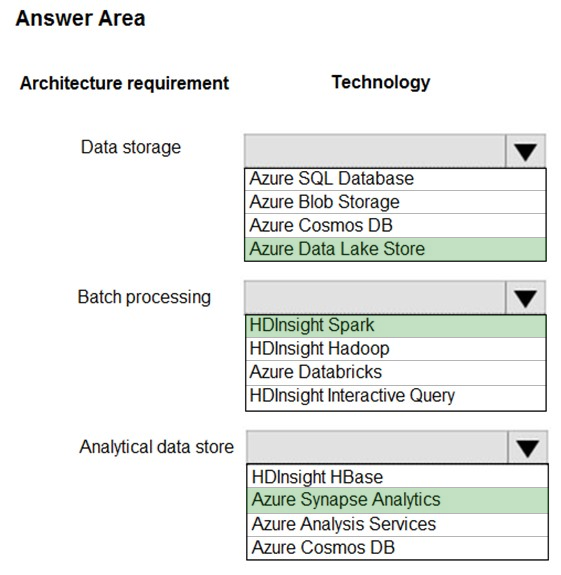
HOTSPOT -
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at rest layer must meet the following requirements:
Data storage:
✑ Serve as a repository for high volumes of large files in various formats.
✑ Implement optimized storage for big data analytics workloads.
✑ Ensure that data can be organized using a hierarchical structure.
Batch processing:
✑ Use a managed solution for in-memory computation processing.
✑ Natively support Scala, Python, and R programming languages.
✑ Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
✑ Support parallel processing.
✑ Use columnar storage.
✑ Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area: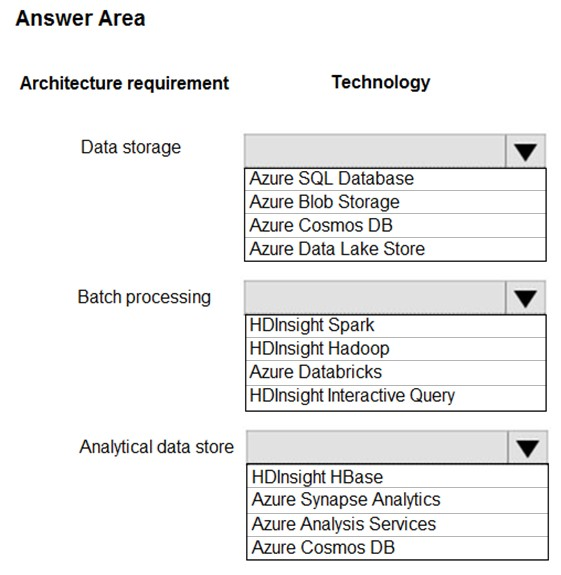

gallego82
Highly Voted 4 years agoPairon
Highly Voted 4 years agoPalp
Most Recent 3 years, 10 months agoAZ20
3 years, 10 months agoMYR55
3 years, 11 months agoeurekamike
3 years, 10 months agomaciejt
3 years, 11 months agoNamishBansal
3 years, 11 months agossanka
4 years agomeswapnilspal
3 years, 12 months agoWendy_DK
4 years agoManoel_Benicio
4 years agoLG5
4 years agoeliabsbueno
4 years ago