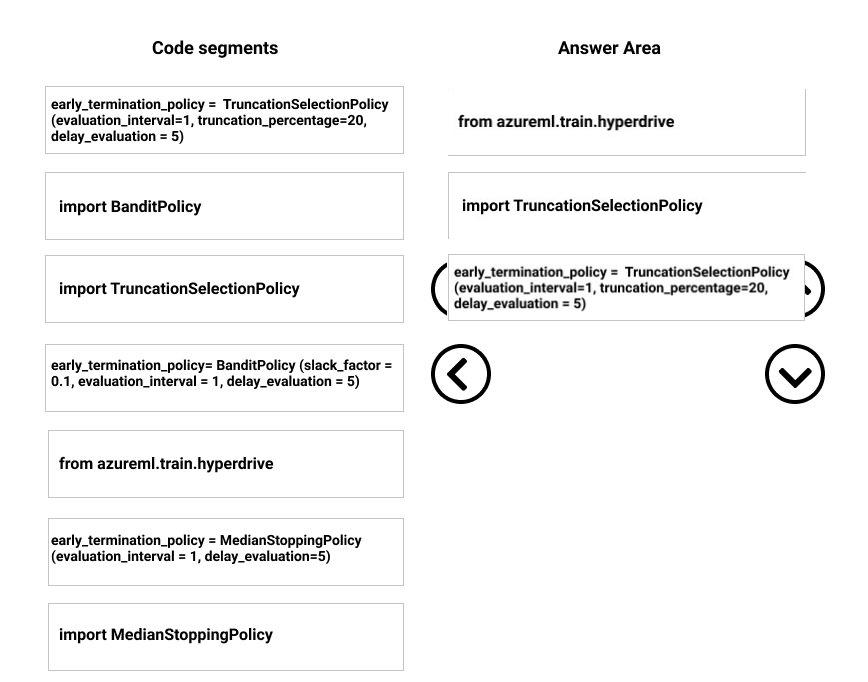
DRAG DROP -
You need to implement early stopping criteria as stated in the model training requirements.
Which three code segments should you use to develop the solution? To answer, move the appropriate code segments from the list of code segments to the answer area and arrange them in the correct order.
NOTE: More than one order of answer choices is correct. You will receive the credit for any of the correct orders you select.
Select and Place: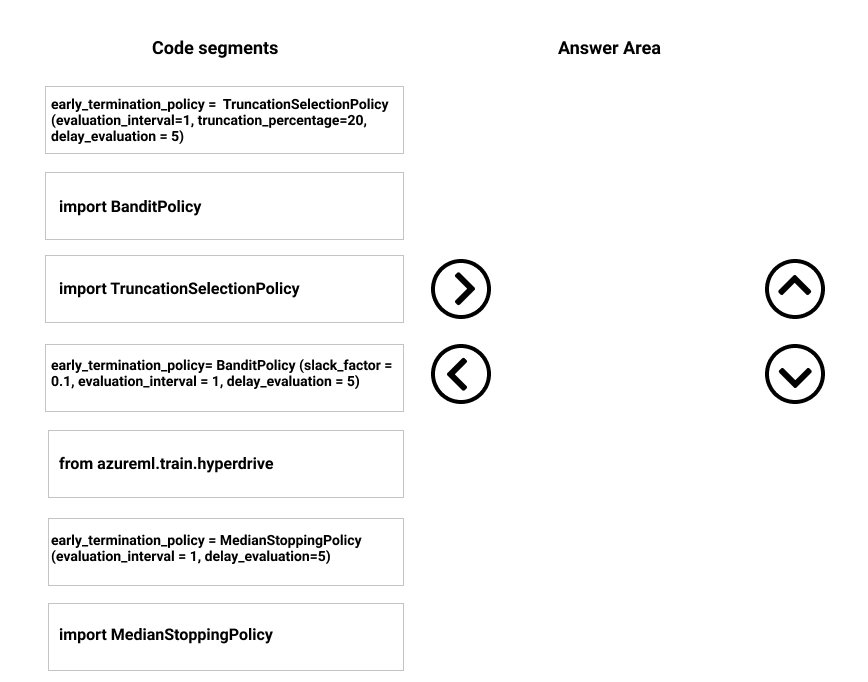

yobllip
Highly Voted 2 years, 9 months agojames2033
Most Recent 6 months agophdykd
1 year, 1 month agosynapse
2 years agohargur
2 years, 6 months agoLucario95
2 years, 11 months agosaurabhk1
3 years, 1 month agoaudun
2 years ago