A company wants to classify user behavior as either fraudulent or normal. Based on internal research, a Machine Learning Specialist would like to build a binary classifier based on two features: age of account and transaction month. The class distribution for these features is illustrated in the figure provided.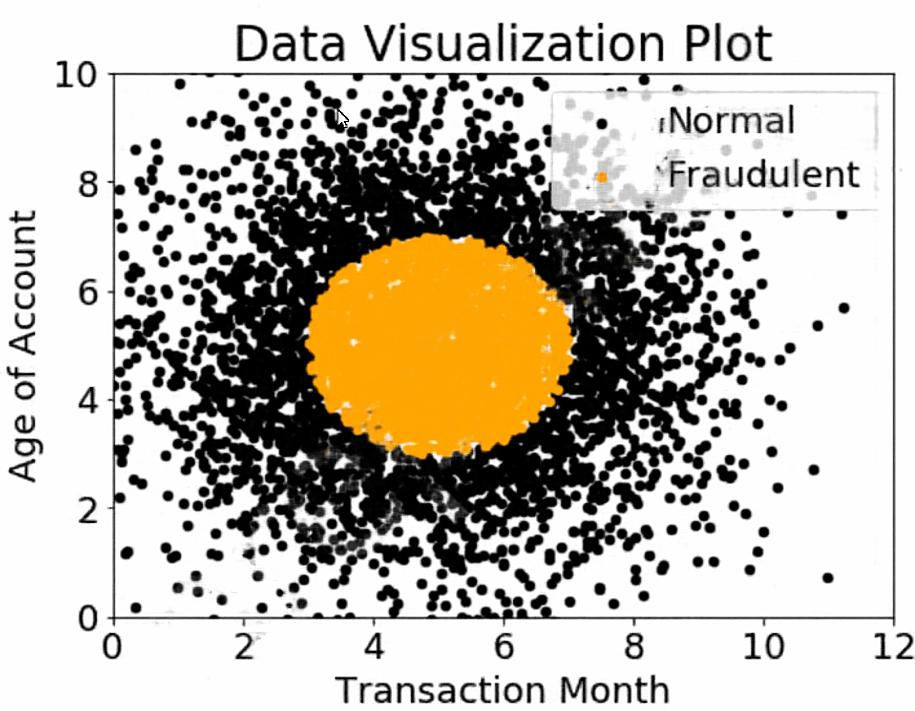
Based on this information, which model would have the HIGHEST recall with respect to the fraudulent class?

E_aws
Highly Voted 3 years, 8 months agoE_aws
3 years, 8 months agoblubb
Highly Voted 3 years, 8 months agoJonSno
Most Recent 4 months, 3 weeks agoMVAS
5 months agoMintTeaClarity
7 months, 4 weeks agoegorkrash
8 months, 2 weeks agoMultiCloudIronMan
8 months, 3 weeks agoML_2
11 months agoninomfr64
1 year agoGrumpyApple
7 months, 3 weeks agoiambasspaul
1 year, 2 months agorav009
1 year, 4 months agonotbother123
1 year, 4 months agokyuhuck
1 year, 5 months agophdykd
1 year, 6 months agophdykd
1 year, 6 months agotaustin2
1 year, 7 months agoakgarg00
1 year, 8 months ago